
Menu:
Behrooz Parhami's Textbook on Parallel Processing

Page last updated on 2021 February 12
B. Parhami, Introduction to Parallel Processing: Algorithms and Architectures, Plenum, New York, 1999. (ISBN 0-306-45970-1, 532+xxi pages, 301 figures, 358 end-of-chapter problems)
Available for purchase from Springer Science and various college or on-line bookstores. Instructor's solutions manual is provided gratis by Springer to instructors who adopt the textbook.
Presentations, Lecture Slides (in PowerPoint & PDF formats)
Preface (with contents-at-a-glance and list of general references)
Book Reviews
Complete Table of Contents
Instructor's Solutions Manual (Preface, and how to order)
List of Errors (for the text and its solutions manual)
Additions to the Text, and Internet Resources
Four New Chapters (Part II expanded from 4 to 8 chapters)
Author's Graduate Course on Parallel Processing
Presentations, Lecture Slides
The following PowerPoint and PDF presentations for the six parts of the textbook are available for downloading (file sizes up to 3 MB). These presentation files were originally prepared in 2005 and were last updated on the dates shown. Slides for the original Part II are still available (ppt, pdf, last updated 2008/10/22), even though they have been superseded by their expansion into Parts II' and II", beginning in 2010.
 Part I: Fundamental Concepts (ppt, pdf, last updated 2021/01/01)
Part I: Fundamental Concepts (ppt, pdf, last updated 2021/01/01)
Part II': Shared-Memory Parallelism (ppt, pdf, last updated 2021/01/11)
Part II": Parallelism at the Circuit Level (ppt, pdf, last updated 2021/01/15)
Part III: Mesh-Based Architectures (ppt, pdf, last updated 2021/02/01)
Part IV: Low-Diameter Architectures (ppt, pdf, last updated 2021/02/07)
Part V: Some Broad Topics (ppt, pdf, last updated 2021/02/12)
Part VI: Implementation Aspects (ppt, pdf, last updated 2010/11/24)
The following versions of the Instructor's Manual, Vol. 2, are available for downloading in PS and PDF formats, but they have been superseded by the lecture slides above.
Instructor's Manual—Vol. 2: Spring 2000 (ps, 5 MB; pdf, 1 MB, incomplete)
Instructor's Manual—Vol. 2: Winter 2002 (ps, 19 MB; pdf, 43 MB)
Preface
The context of parallel processing

The field of digital computer architecture has grown explosively in the past two decades. Through a steady stream of experimental research, tool-building efforts, and theoretical studies, the design of an instruction-set architecture, once considered an art, has been transformed into one of the most quantitative branches of computer technology. At the same time, better understanding of various forms of concurrency, from standard pipelining to massive parallelism, and invention of architectural structures to support a reasonably efficient and user-friendly programming model for such systems, has allowed hardware performance to continue its exponential growth. This trend is expected to continue in the near future.
This explosive growth, linked with the expectation that performance will continue its exponential rise with each new generation of hardware and that (in stark contrast to software) computer hardware will function correctly as soon as it comes off the assembly line, has its down side. It has led to unprecedented hardware complexity and almost intolerable development costs. The challenge facing current and future computer designers is to institute simplicity where we now have complexity; to use fundamental theories being developed in this area to gain performance and ease-of-use benefits from simpler circuits; to understand the interplay between technological capabilities and limitations, on the one hand, and design decisions based on user and application requirements on the other.
In the computer designers' quest for user-friendliness, compactness, simplicity, high performance, low cost, and low power, parallel processing plays a key role. High-performance uniprocessors are becoming increasingly complex, expensive, and power-hungry. A basic tradeoff thus exists between the use of one or a small number of such complex processors, at one extreme, and a moderate to very large number of simpler processors, at the other. When combined with a high-bandwidth, but logically simple, interprocessor communication facility, the latter approach leads to significant simplification of the design process. However, two major roadblocks have thus far prevented the widespread adoption of such moderately to massively parallel architectures: the interprocessor communication bottleneck and the difficulty, and thus high cost, of algorithm/software development.
The above context is changing due to several factors. First, at very high clock rates, the link between the processor and memory becomes very critical. CPUs can no longer be designed and verified in isolation. Rather, an integrated processor/memory design optimization is required which makes the development even more complex and costly. VLSI technology now allows us to put more transistors on a chip than required by even the most advanced superscalar processor. The bulk of these transistors are now being used to provide additional on-chip memory. However, they can just as easily be used to build multiple processors on a single chip. Emergence of multiple-processor microchips, along with currently available methods for glueless combination of several chips into a larger system and maturing standards for parallel machine models, holds the promise for making parallel processing more practical.
This is why parallel processing occupies such a prominent place in computer architecture education and research. New parallel architectures appear with amazing regularity in technical publications, while older architectures are studied and analyzed in novel and insightful ways. The wealth of published theoretical and practical results on parallel architectures and algorithms is truly awe-inspiring. The emergence of standard programming and communication models has removed some of the concerns with compatibility and software design issues in parallel processing, thus resulting in new designs and products with mass-market appeal. Given the computation-intensive nature of many application areas (such as encryption, physical modeling, and multimedia), parallel processing will continue to thrive for years to come.
Perhaps, as parallel processing matures further, it will start to become invisible. Packing many processors in a computer might constitute as much a part of a future computer architect's toolbox as pipelining, cache memories, and multiple instruction issue do today. In this scenario, even though the multiplicity of processors will not affect the end user or even the professional programmer (other than of course boosting the system performance), the number might be mentioned in sales literature to lure customers, in the same way that clock frequency and cache size are now used. The challenge will then shift from making parallel processing work to incorporating a larger number of processors, more economically and in a truly seamless fashion.
The goals and structure of this book
The field of parallel processing has matured to the point that scores of texts and reference books have been published. Some of these books that cover parallel processing in general (as opposed to some special aspects of the field or advanced/unconventional parallel systems) are listed at the end of this preface. Each of these books has its unique strengths and has contributed to the formation and fruition of the field. The current text, Introduction to Parallel Processing: Algorithms and Architectures, is an outgrowth of lecture notes that the author has developed and refined over many years, beginning in the mid-1980s. Here are the most important features of this text in comparison to the listed books:
1. Division of material into lecture-size chapters. In my approach to teaching, a lecture is a more or less self-contained module with links to past lectures and pointers to what will transpire in the future. Each lecture must have a theme or title and must proceed from motivation, to details, to conclusion. There must be smooth transitions between lectures and a clear enunciation of how each lecture fits into the overall plan. In designing the text, I have strived to divide the material into chapters, each of which is suitable for one lecture (1-2 hours). A short lecture can cover the first few subsections while a longer lecture might deal with more advanced material near the end. To make the structure hierarchical, as opposed to flat or linear, chapters have been grouped into six parts, each composed of four closely related chapters (see the diagram above).
2. A large number of meaningful problems. At least 13 problems have been provided at the end of each of the 24 chapters. These are well-thought-out problems, many of them class-tested, that complement the material in the chapter, introduce new viewing angles, and link the chapter material to topics in other chapters.
3. Emphasis on both the underlying theory and practical designs. The ability to cope with complexity requires both a deep knowledge of the theoretical underpinnings of parallel processing and examples of designs that help us understand the theory. Such designs also provide hints/ideas for synthesis as well as reference points for cost-performance comparisons. This viewpoint is reflected, e.g., in the coverage of problem-driven parallel machine designs (Chapter 8) that point to the origins of the butterfly and binary-tree architectures. Other examples are found in Chapter 16 where a variety of composite and hierarchical architectures are discussed and some fundamental cost-performance trade-offs in network design are exposed. Fifteen carefully chosen case studies in Chapters 21-23 provide additional insight and motivation for the theories discussed.
4. Linking parallel computing to other subfields of computer design. Parallel computing is nourished by, and in turn feeds, other subfields of computer architecture and technology. Examples of such links abound. In computer arithmetic, the design of high-speed adders and multipliers contributes to, and borrows many methods from, parallel processing. Some of the earliest parallel systems were designed by researchers in the field of fault-tolerant computing in order to allow independent multichannel computations and/or dynamic replacement of failed subsystems. These links are pointed out throughout the book.
5. Wide coverage of important topics. The current text covers virtually all important architectural and algorithmic topics in parallel processing, thus offering a balanced and complete view of the field. Coverage of the circuit model and problem-driven parallel machines (Chapters 7 and 8), some variants of mesh architectures (Chapter 12), composite and hierarchical systems (Chapter 16), which are becoming increasingly important for overcoming VLSI layout and packaging constraints, and the topics in Part V (Chapters 17-20) do not all appear in other textbooks. Similarly, other books that cover the foundations of parallel processing do not contain discussions on practical implementation issues and case studies of the type found in Part VI.
6. Unified and consistent notation/terminology throughout the text. I have tried very hard to use consistent notation/terminology throughout the text. For example, n always stands for the number of data elements (problem size) and p for the number of processors. While other authors have done this in the basic parts of their texts, there is a tendency to cover more advanced research topics by simply borrowing the notation and terminology from the reference source. Such an approach has the advantage of making the transition between reading the text and the original reference source easier, but it is utterly confusing to the majority of the students who rely on the text and do not consult the original references except, perhaps, to write a research paper.
Summary of topics
The six parts of this book, each composed of four chapters, have been written with the following goals:
Part I sets the stage, gives a taste of what is to come, and provides the needed perspective, taxonomy, and analysis tools for the rest of the book.
Part II delimits the models of parallel processing from above (the abstract PRAM model) and from below (the concrete circuit model), preparing the reader for everything else that falls in the middle.
Part III presents the scalable, and conceptually simple, mesh model of parallel processing, which has become quite important in recent years, and also covers some of its derivatives.
Part IV covers low-diameter parallel architectures and their algorithms, including the hypercube, hypercube derivatives, and a host of other interesting interconnection topologies.
Part V includes broad (architecture-independent) topics that are relevant to a wide range of systems and form the stepping stones to effective and reliable parallel processing.
Part VI deals with implementation aspects and properties of various classes of parallel processors, presenting many case studies and projecting a view of the past and future of the field.
Pointers on how to use the book
For classroom use, the topics in each chapter of this text can be covered in a lecture spanning 1-2 hours. In my own teaching, I have used the chapters primarily for 1.5-hour lectures, twice a week, in a 10-week quarter, omitting or combining some chapters to fit the material into 18-20 lectures. But the modular structure of the text lends itself to other lecture formats, self-study, or review of the field by practitioners. In the latter two cases, the readers can view each chapter as a study unit (for 1 week, say) rather than as a lecture. Ideally, all topics in each chapter should be covered before moving to the next chapter. However, if fewer lecture hours are available, then some of the subsections located at the end of chapters can be omitted or introduced only in terms of motivations and key results.
Problems of varying complexities, from straightforward numerical examples or exercises to more demanding studies or miniprojects, have been supplied for each chapter. These problems form an integral part of the book and have not been added as afterthoughts to make the book more attractive for use as a text. A total of 358 problems are included (13-16 per chapter). Assuming that two lectures are given per week, either weekly or biweekly homework can be assigned, with each assignment having the specific coverage of the respective half-part (two chapters) or full part (four chapters) as its "title." In this format, the half-parts, shown in the diagram above, provide a focus for the weekly lecture and/or homework schedule.
An instructor's manual, with problem solutions and enlarged versions of the diagrams and tables, suitable for reproduction as transparencies, is planned. The author's detailed syllabus for the course ECE 254B at UCSB is available from the author's Web page for the course.
References to important or state-of-the-art research contributions and designs are provided at the end of each chapter. These references provide good starting points for doing in-depth studies or for preparing term papers/projects.
New ideas in the field of parallel processing appear in papers presented at several annual conferences, known as FMPC, ICPP, IPPS, SPAA, SPDP (now merged with IPPS), and in archival journals such as IEEE Transactions on Computers [Tcom], IEEE Transactions on Parallel and Distributed Systems [TPDS], Journal of Parallel and Distributed Computing [JPDC], Parallel Computing [ParC], and Parallel Processing Letters [PPL]. Tutorial and survey papers of wide scope appear in IEEE Concurrency [Conc] and, occasionally, in IEEE Computer [Comp]. The articles in IEEE Computer provide excellent starting points for research projects and term papers.
Acknowledgments
The current text, Introduction to Parallel Processing: Algorithms and Architectures, is an outgrowth of lecture notes that the author has used for the graduate course "ECE 254B: Advanced Computer Architecture: Parallel Processing" at the University of California, Santa Barbara, and, in rudimentary forms, at several other institutions prior to 1988. The text has benefited greatly from keen observations, curiosity, and encouragement of my many students in these courses. A sincere thanks to all of them! Particular thanks go to Dr. Ding-Ming Kwai who read an early version of the manuscript carefully and suggested numerous corrections and improvements.
General references
[Akl89] Akl, S. G., The Design and Analysis of Parallel Algorithms, Prentice Hall, 1989.
[Akl97] Akl, S. G., Parallel Computation: Models and Methods, Prentice Hall, 1997.
[Alma94] Almasi, G. S. and A. Gottlieb, Highly Parallel Computing, Benjamin/Cummings, 2nd Ed., 1994.
[Bert89] Bertsekas, D. P. and J. N. Tsitsiklis, Parallel and Distributed Computation: Numerical Methods, Prentice Hall, 1989.
[Code93] Codenotti, B. and M. Leoncini, Introduction to Parallel Processing, Addison-Wesley, 1993.
[Comp] IEEE Computer, Journal published by IEEE Computer Society; has occasional special issues on parallel/distributed Processing (February 1982, June 1985, August 1986, June 1987, March 1988, August 1991, February 1992, November 1994, November 1995, December 1996).
[Conc] IEEE Concurrency, formerly IEEE Parallel & Distributed Technology, Magazine published by IEEE Computer Society.
[Cric88] Crichlow, J. M., Introduction to Distributed and Parallel Computing, Prentice Hall, 1988.
[DeCe89] DeCegama, A. L., Parallel Processing Architectures and VLSI Hardware, Prentice Hall, 1989.
[Desr87] Desrochers, G. R., Principles of Parallel and Multiprocessing, McGraw-Hill, 1987.
[Duat97] Duato, J., S. Yalamanchili, and L. Ni, Interconnection Networks: An Engineering Approach, IEEE Computer Society Press, 1997.
[Flyn95] Flynn, M. J., Computer Architecture: Pipelined and Parallel Processor Design, Jones and Bartlett, 1995.
[FMPC] Proc. Symp. Frontiers of Massively Parallel Computation, Sponsored by IEEE Computer Society and NASA. Held every 1.5-2 years since 1986. The 6th FMPC was held in Annapolis, MD, October 27-31, 1996, and the 7th is planned for February 20-25, 1999.
[Foun94] Fountain, T. J., Parallel Computing: Principles and Practice, Cambridge University Press, 1994.
[Hock81] Hockney, R. W. and C. R. Jesshope, Parallel Computers, Adam Hilger, 1981.
[Hord90] Hord, R. M., Parallel Supercomputing in SIMD Architectures, CRC Press, 1990.
[Hord93] Hord, R. M., Parallel Supercomputing in MIMD Architectures, CRC Press, 1993.
[Hwan84] Hwang, K. and F. A. Briggs, Computer Architecture and Parallel Processing, McGraw-Hill, 1984.
[Hwan93] Hwang, K., Advanced Computer Architecture: Parallelism, Scalability, Programmability, McGraw-Hill, 1993.
[Hwan98] Hwang, K. and Z. Xu, Scalable Parallel Computing: Technology, Architecture, Programming, McGraw-Hill, 1998.
[ICPP] Proc. Int'l Conference Parallel Processing, Sponsored by The Ohio State University (and in recent years, also by the Int'l Association for Computers and Communications). Held annually since 1972. The 27th ICPP was held in Minneapolis, MN, August 10-15, 1998, and the 28th is scheduled for September 21-24, 1999, in Aizu, Japan.
[IPPS] Proc. Int'l Parallel Processing Symp., Sponsored by IEEE Computer Society. Held annually since 1987. The 11th IPPS was held in Geneva, Switzerland, April 1-5, 1997. Beginning with the 1988 symposium in Orlando, FL, March 30 – April 3, IPPS was merged with SPDP. The next joint IPPS/SPDP is scheduled for April 12-16, 1999, in San Juan, Puerto Rico.
[JaJa92] JaJa, J., An Introduction to Parallel Algorithms, Addison-Wesley, 1992.
[JPDC] Journal of Parallel & Distributed Computing, Published by Academic Press.
[Kris89] Krishnamurthy, E. V., Parallel Processing: Principles and Practice, Addison-Wesley, 1989.
[Kuma94] Kumar, V., A. Grama, A. Gupta, and G. Karypis, Introduction to Parallel Computing: Design and Analysis of Algorithms, Benjamin/Cummings, 1994.
[Laks90] Lakshmivarahan, S. and S. K. Dhall, Analysis and Design of Parallel Algorithms: Arithmetic and Matrix Problems, McGraw-Hill, 1990.
[Leig92] Leighton, F. T., Introduction to Parallel Algorithms and Architectures: Arrays, Trees, Hypercubes, Morgan Kaufman, 1992.
[Lerm94] Lerman, G. and L. Rudolph, Parallel Evolution of Parallel Processors, Plenum, 1994.
[Lipo87] Lipovski, G. J. and M. Malek, Parallel Computing: Theory and Comparisons, Wiley, 1987.
[Mold93] Moldovan, D. I., Parallel Processing: From Applications to Systems, Morgan Kaufmann, 1993.
[ParC] Parallel Computing, Journal published by North-Holland.
[PPL] Parallel Processing Letters, Journal published by World Scientific.
[Quin87] Quinn, M. J., Designing Efficient Algorithms for Parallel Computers, McGraw-Hill, 1987.
[Quin94] Quinn, M. J., Parallel Computing: Theory and Practice, McGraw-Hill, 1994.
[Reif93] Reif, J. H. (ed.), Synthesis of Parallel Algorithms, Morgan Kaufmann, 1993.
[Sanz89] Sanz, J. L. C. (ed.), Opportunities and Constraints of Parallel Computing (IBM/NSF Workshop, San Jose, CA, December 1988), Springer-Verlag, 1989.
[Shar87] Sharp, J. A., An Introduction to Distributed and Parallel Processing, Blackwell Scientific Publications, 1987.
[Sieg85] Siegel, H. J., Interconnection Networks for Large-Scale Parallel Processing, Lexington Books, 1985.
[SPAA] Proc. Symp. Parallel Algorithms and Architectures, Sponsored by the Association for Computing Machinery (ACM). Held annually since 1989. The 10th SPAA was held in Puerto Vallarta, Mexico, June 28 – July 2, 1998.
[SPDP] Proc. Int'l Symp. Parallel & Distributed Systems, Sponsored by IEEE Computer Society. Held annually since 1989, except for 1997. The 8th SPDP was held in New Orleans, LA, October 23-26, 1996. Beginning with the 1998 symposium in Orlando, FL, March 30 – April 3, SPDP was merged with IPPS.
[Ston93] Stone, H. S., High-Performance Computer Architecture, Addison-Wesley, 1993.
[TCom] IEEE Trans. Computers, Journal published by IEEE Computer Society; has occasional special issues on parallel and distributed processing (April 1987, December 1988, August 1989, December 1991, April 1997, April 1998).
[TPDS] IEEE Trans. Parallel and Distributed Systems, Journal published by IEEE Computer Society.
[Varm94] Varma, A. and C. S. Raghavendra, Interconnection Networks for Multiprocessors and Multicomputers: Theory and Practice, IEEE Computer Society Press, 1994.
[Zoma96] Zomaya, A. Y. (ed.), Parallel and Distributed Computing Handbook, McGraw-Hill, 1996.
Book Reviews
The following review appreared in Scalable Computing: Practice and Experience, Vol. 4, No. 1, 2001.
The book is organized in a very structured way making it suitable for use in a senior-level undergraduate or an introductory-level graduate course in computer science/engineering. While being successful in covering the main topics of parallel processing, the author has managed to arrive at an evenly divided book with fairly self-contained sections. As shown in page (xi), the book is comprised of six parts with each part containing four chapters. In the book, theoretical models of parallel processing are described and accompanied by techniques for exact analysis of parallel machines. The focus of the book is mainly on hardware issues, and software aspects such as parallel compilers/operating systems and concurrent programming are addressed in less detail.
From the start, the author motivates the problem by explaining the continuing need for parallel processing regardless of advances in technology. Chapter 1 dwells on basic concepts of parallel processing. Fundamental computations including semigroup and parallel prefix computations are covered in Chapter 2. The reader here is introduced to simple parallel architectures such as linear array, binary tree, and 2D mesh. Most common communication primitives such as one to one routing, broadcasting, and sorting are described in conjunction with the said three architectures. In Chapter 3, asymptotic complexity along with complexity classes (NP-complete, NP, P, NC, etc.) is covered in detail. The author has done a good job in clarifying facts and fallacies of parallel processing. Chapter 4 concludes the first part of the book by intruding Flynn's classification of parallel machines, the PRAM model, and global versus distributed memory.
Part II starts out with the PRAM as an extreme model for parallel computation. It then describes, in more detail than earlier chapters, the basic parallel algorithms. Algorithms aimed at systems with shared memory are discussed in Chapter 6. Synthesis and analysis of sorting networks are presented in Chapter 7, which is followed by more coverage of architectures designed for such parallel algorithms as DFT and FFT.
Part III is devoted to mesh-based networks with associated algorithms. These networks are important due to their simplicity and low communication delay; they form the backbone of many parallel machines. I think, therefore, devotion of the whole part to mesh topologies is appropriate and well justified.
Part IV covers the popular networks proposed over the past decades to serve as the underlying topology of parallel machines. These networks generally have low diameter and node degree and offer the familiar trade-off between speed and cost.
Part V presents broad topics such as data flow, load balancing, and scheduling as well as system issues. Emulation (embedding) among parallel architectures is also discussed in a general way, with specific problems given at the end of the chapter.
Finally Part VI adds much value to the text by addressing the implementation issues and introducing the contemporary parallel machines of different types.
The book also contains useful and informative examples, illustrations, and problems. The end-of-chapter exercises are rigorous and relate directly to the subject just covered. References are recent and are taken from highly visible conferences/journals and books in the discipline.
Finally, it should be pointed out that writing a book on computer architecture in general and parallel processing in particular is a challenge considering recent advances in technology. The author should be congratulated for composing a book, which appears to survive for years to come as it addresses, along with contemporary algorithms and architectures, concepts and innovations with little or no dependence on the current technology.
Shahram Latifi
University of Nevada, Las Vegas
Complete Table of Contents
Note: Each chapter ends with sections entitled "Problems" and "References and Suggested Reading."
Part I: Fundamental Concepts
1 Introduction to Parallelism ~
1.1 Why Parallel Processing? ~
1.2 A Motivating Example ~
1.3 Parallel Processing Ups and Downs ~
1.4 Types of Parallelism: A Taxonomy ~
1.5 Roadblocks to Parallel Processing ~
1.6 Effectiveness of Parallel Processing
2 A Taste of Parallel Algorithms ~
2.1 Some Simple Computations ~
2.2 Some Simple Architectures ~
2.3 Algorithms for a Linear Array ~
2.4 Algorithms for a Binary Tree ~
2.5 Algorithms for a 2D Mesh ~
2.6 Algorithms with Shared Variables
3 Parallel Algorithm Complexity ~
3.1 Asymptotic Complexity ~
3.2 Algorithm Optimality and Efficiency ~
3.3 Complexity Classes ~
3.4 Parallelizable Tasks and the NC Class ~
3.5 Parallel Programming Paradigms ~
3.6 Solving Recurrences
4 Models of Parallel Processing ~
4.1 Development of Early Models ~
4.2 SIMD versus MIMD Architectures ~
4.3 Global versus Distributed Memory ~
4.4 The PRAM Shared-Memory Model ~
4.5 Distributed-Memory or Graph Models ~
4.6 Circuit Model and Physical Realizations
Part II: Extreme Models
5 PRAM and Basic Algorithms ~
5.1 PRAM Submodels and Assumptions ~
5.2 Data Broadcasting ~
5.3 Semigroup or Fan-in Computation ~
5.4 Parallel Prefix Computation ~
5.5 Ranking the Elements of a Linked List ~
5.6 Matrix Multiplication
6 More Shared-Memory Algorithms ~
6.1 Sequential Ranked-Based Selection ~
6.2 A Parallel Selection Algorithm ~
6.3 A Selection-Based Sorting Algorithm ~
6.4 Alternative Sorting Algorithms ~
6.5 Convex Hull of a 2D Point Set ~
6.6 Some Implementation Aspects
7 Sorting and Selection Networks ~
7.1 What is a Sorting Network? ~
7.2 Figures of Merit for Sorting Networks ~
7.3 Design of Sorting Networks ~
7.4 Batcher Sorting Networks ~
7.5 Other Classes of Sorting Networks ~
7.6 Selection Networks
8 Other Circuit-Level Examples ~
8.1 Searching and Dictionary Operations ~
8.2 A Tree-Structured Dictionary Machine ~
8.3 Parallel Prefix Computation ~
8.4 Parallel Prefix Networks ~
8.5 The Discrete Fourier Transform ~
8.6 Parallel Architectures for FFT
Part III: Mesh-Based Architectures
9 Sorting on a 2D Mesh or Torus ~
9.1 Mesh-Connected Computers ~
9.2 The Shearsort Algorithm ~
9.3 Variants of Simple Shearsort ~
9.4 Recursive Sorting Algorithms ~
9.5 A Nontrivial Lower Bound ~
9.6 Achieving the Lower Bound
10 Routing on a 2D Mesh or Torus ~
10.1 Types of Data Routing Operations ~
10.2 Useful Elementary Operations ~
10.3 Data Routing on a 2D Array ~
10.4 Greedy Routing Algorithms ~
10.5 Other Classes of Routing Algorithms ~
10.6 Wormhole Routing
11 Numerical 2D Mesh Algorithms ~
11.1 Matrix Multiplication ~
11.2 Triangular System of Equations ~
11.3 Tridiagonal System of Linear Equations ~
11.4 Arbitrary System of Linear Equations ~
11.5 Graph Algorithms ~
11.6 Image-Processing Algorithms
12 Other Mesh-Related Architectures ~
12.1 Three or More Dimensions ~
12.2 Stronger and Weaker Connectivities ~
12.3 Meshes Augmented with Nonlocal Links ~
12.4 Meshes with Dynamic Links ~
12.5 Pyramid and Multigrid Systems ~
12.6 Meshes of Trees
Part IV: Low-Diameter Architectures
13 Hypercubes and Their Algorithms ~
13.1 Definition and Main Properties ~
13.2 Embeddings and Their Usefulness ~
13.3 Embeddings of Arrays and Trees ~
13.4 A Few Simple Algorithms ~
13.5 Matrix Multiplication ~
13.6 Inverting a Lower Triangular Matrix
14 Sorting and Routing on Hypercubes ~
14.1 Defining the Sorting Problem ~
14.2 Bitonic Sorting ~
14.3 Routing Problems on a Hypercube ~
14.4 Dimension-Order Routing ~
14.5 Broadcasting on a Hypercube ~
14.6 Adaptive and Fault-Tolerant Routing
15 Other Hypercubic Architectures ~
15.1 Modified and Generlized Hypercubes ~
15.2 Butterfly and Permutation Networks ~
15.3 Plus-or-Minus-2i Network ~
15.4 The Cube-Connected Cycles ~
15.5 Shuffle and Shuffle-Exchange Networks ~
15.6 That's Not All, Folks!
16 A Sampler of Other Networks ~
16.1 Performance Parameters for Networks ~
16.2 Star and Pancake Networks ~
16.3 Ring-Based Networks ~
16.4 Composite or Hybrid Networks ~
16.5 Hierarchical (Multilevel) Networks ~
16.6 Multistage Interconnection Networks
Part V: Some Broad Topics
17 Emulation and Scheduling ~
17.1 Emulations Among Architectures ~
17.2 Distributed Shared Memory ~
17.3 The Task Scheduling Problem ~
17.4 A Class of Scheduling Algorithms ~
17.5 Some Useful Bounds for Scheduling ~
17.6 Load Balancing and Dataflow Systems
18 Data Storage, Input, and Output ~
18.1 Data Access Problems and Caching ~
18.2 Cache Coherence Protocols ~
18.3 Multithreading and Latency Hiding ~
18.4 Parallel I/O Technology ~
18.5 Redundant Disk Arrays ~
18.6 Interfaces and Standards
19 Reliable Parallel Processing ~
19.1 Defect, Faults, ... , Failures ~
19.2 Defect-Level Methods ~
19.3 Fault-Level Methods ~
19.4 Error-Level Methods ~
19.5 Malfunction-Level Methods ~
19.6 Degradation-Level Methods
20 System and Software Issues ~
20.1 Coordination and Synchronization ~
20.2 Parallel Programming ~
20.3 Software Portability and Standards ~
20.4 Parallel Operating Systems ~
20.5 Parallel File Systems ~
20.6 Hardware/Software Interaction
Part VI: Implementation Aspects
21 Shared-Memory MIMD Machines ~
21.1 Variations in Shared Memory ~
21.2 MIN-Based BBN Butterfly ~
21.3 Vector-Parallel Cray Y-MP ~
21.4 Latency-Tolerant Tera MTA ~
21.5 CC-NUMA Stanford DASH ~
21.6 SCI-Based Sequent NUMA-Q
22 Message-Passing MIMD Machines ~
22.1 Mechanisms for Message Passing ~
22.2 Reliable Bus-Based Tandem NonStop ~
22.3 Hypercube-Based nCUBE3 ~
22.4 Fat-Tree-Based Connection Machine 5 ~
22.5 Omega-Network-Based IBM SP2 ~
22.6 Commodity-Driven Berkeley NOW
23 Data-Parallel SIMD Machines ~
23.1 Where Have All the SIMDs Gone? ~
23.2 The First Suprcomputer: ILLIAC IV ~
23.3 Massively Parallel Goodyear MPP ~
23.4 Distributed Array Processor (DAP) ~
23.5 Hypercubic Connection Machine 2 ~
23.6 Multiconnected MasPar MP-2
24 Past, Present, and Future ~
24.1 Milestones in Parallel Processing ~
24.2 Current Status, Issues, and Debates ~
24.3 TFLOPS, PFLOPS, and Beyond ~
24.4 Processor and Memory Technologies ~
24.5 Interconnection Technologies ~
24.6 The Future of Parallel Processing
Preface to the Instructor's Solutions Manual
This instructor's manual consists of two volumes. Volume 1 presents solutions to selected problems and includes additional problems (many with solutions) that did not make the cut for inclusion in the text Introduction to Parallel Processing: Algorithms and Architectures (Plenum Press, 1999) or that were designed after the book went to print. Volume 2 contains enlarged versions of the figures and tables in the text as well as additional material, presented in a format that is suitable for use as transparency masters.
The winter 2002 edition Volume 1, which consists of the following parts, is available to qualified instructors through the publisher.
Part I: Selected solutions and additional problems
Part II: Question bank, assignments, and projects
The winter 2002 edition of Volume 2, which consists of the following parts, is available as a large downloadable file through the book's Web page.
Parts I-VI: Lecture slides and other presentation material
The book's Web page, given below, also contains an errata and a host of other material:
http://www.ece.ucsb.edu/~parhami/text_par_proc.htm
The author would appreciate the reporting of any error in the textbook or in this manual, suggestions for additional problems, alternate solutions to solved problems, solutions to other problems, and sharing of teaching experiences. Please e-mail your comments to "parhami at ece dot ucsb dot edu" or send them by regular mail to the author's postal address:
Department of Electrical and Computer Engineering
University of California
Santa Barbara, CA 93106-9560, USA
Contributions will be acknowledged to the extent possible.
List of Errors

The following corrections are presented in the order of page numbers in the book. Each entry is assigned a unique code, which appears in square brackets and begins with the date of posting or last modification in the format "yymmdd." As errors are removed in future printings, the codes will be augmented to include the printing number which no longer contains the error.
Note: To find out which printing of the book you own, look at the bottom of the copyright page; there, you see a sequence of numbers "10 9 8 . . . ." the last of which is the printing.
p. 10 [010410c] In Fig. 1.5, lower right corner, the label "(b)" is redundant and should be removed.
p. 13 [010410d] In the right panel of Fig. 1.9, replace "Real" with "Actual".
p. 21 [030220] In Problem 1.1, part a, replace "MIPS rating" by "IPS rating".
p. 21 [001212] In Problem 1.5, replace "For each of the values, 1, 10, and 100 for the parameter b, determine the range of values for c where ..." with "Determine the range of values for b and c where ...".
p. 22 [101023] In Problem 1.11, change "single-input device" to "single input device" and "single-output device" to "single output device" (meaning just one input or output device, and not a device with one input).
p. 23 [001212a] Add [Bokh87] to the reference list for Chapter 1.
[Bokh87] Bokhari, S., "Multiprocessing the Sieve of Eratosthenes," IEEE Computer, Vol. 20, No. 4, pp. 50-58, April 1987.
p. 31 [101005] In line 3 of the second paragraph, change "performs a semigroup computation first" to "performs a parallel prefix computation first".
p. 50 [001212b] Table 3.3, leftmost column, last entry: align "1" with the numbers above it.
p. 50 [001212c] Table 3.3, column headed 100 sqrt(n): the first entry should be 5 min (not .5 min).
p. 50 [010410a] Table 3.3, column headed 100 sqrt(n): the next to the last entry should be 9 hr (not 1 yr).
p. 50 [010410b] Table 3.3, column headed 100 sqrt(n): the last entry should be 1 day (not 3 yr).
p. 59 [010330] Near the bottom of the page, the solution given for g(n) = g(n − 1) + 1/2 is incorrect; the correct solution, (n − 1)/2, makes the answer different from that obtained from unrolling. The problem stems from the assumptions f(1) = 0 and g(1) = 0 being incompatible, given the definition f(n) = an2 + g(n). The simplest fix is to replace "g(1) = 0" on the third line from the bottom of the page with "g(2) = 0". An alternate fix is to write f(n) = an2 + g(n) − a on line 9 from the bottom, arguing that this form makes f(1) = g(1) = 0 possible.
p. 97 [030220a] On lines 2 and 3 from bottom, replace "having more processors than items" with "having fewer processors than items".
p. 103 [001212f] Line 3: Change "m2 processors" to "m2 processors" (i.e., italicize m).
p. 113 [210125] Line 4 in the text of the Parallel rank-based selection algorithm: Change "divide S into p subsequences S(j) of size |S|/p" to "divide S into |S|/q subsequences S(j) of size q"
p. 124 [010410] Lines 11-12 are to be slightly modified as follows: This is a butterfly network that we will encounter again in Chapter 8, where we devise a circuit for computing the fast Fourier transform (FFT), and in Chapter 15, (insert two commas and remove "again")
p. 127 [020123] Replace the one-line introduction of Problem 6.14 with the following: Consider the butterfly memory access network depicted in Fig. 6.9, but with only eight processors and eight memory banks, one connected to each circular node in columns 0 and 3 of the butterfly.
p. 134 [081024] In the 9-sorter at the upper left corner of Fig. 7.5, the comparator (vertical line segment) near the right end that connects lines 3 and 7 from the top, should be drawn between lines 3 and 5 from the top.
p. 135 [010501] On line 7 in the first paragraph of Section 7.3, n⌊n/2⌋ should be n(n − 1)/2.
p. 138 [010524] Lines 6-7: The 0s and 1s on line 6, and the wi terms right below them, should be vertically aligned to appear halfway between the 0s and 1s on line 5.
p. 138 [010524a] Last line: The rightmost symbol in the equation for the cost C(n) of Batcher's even-odd-merge sorter should be 4, not 2.
p. 183 [101123] In the second (upper right) panel of Fig. 9.13, the numbers of 0s in two different double-columns can differ by up to 4, not 2. [This error, however, does not invalidate the rest of the proof, as the number of dirty elements in the final (lower left) panel cannot exceed 2 sqrt(p); these elements may span parts of three different rows.]
p. 216 [010516] Replace "back substitution" with "forward substitution" throughout the discussion and in the algorithm title. After the definition of forward substitution, following "... and so forth" add: (the corresponding method for upper triangular systems is called back substitution, because evaluation goes backward from xn−1 to x0).
p. 220 [020308a] In line 2 after Fig. 11.10, change "Θ(√p)" to "Θ(√m)"; that is, replace p with m.
p. 221 [081107d] On line 2, after Fig. 11.11, change "prefix results" to "suffix results".
p. 225 [081107a] In the transitive closure algorithm at the end of the page, insert the following line just before Phase 0: "Initialization: Insert the edges (i, i), 0 ≤ i ≤ n − 1, in the graph."
p. 229 [001212j] In the caption to Figure 11.20, change "Lavialdi's algorithm" to "Levialdi's algorithm in the shrinkage phase" (note spelling correction).
p. 230 [001212k] In the caption to Figure 11.21, change "Lavialdi" to "Levialdi".
p. 231 [001212m] In lines 9 and 22, change "Lavialdi" to "Levialdi".
p. 232 [010516a] Change "Back substitution" in the title and first line of Problem 11.4 to "Forward substitution".
p. 233 [001212n] In the title to Problem 11.13 and in parts a, c, and d, change "Lavialdi" to "Levialdi".
p. 233 [001212p] In the reference labeled [Lavi72], change "Lavialdi" to "Levialdi". Also, change the reference label to [Levi72].
p. 248 [010521] Line 8: Change the exponent of 2 from 2l − 2 to l − 2; i.e., the number of processors in an l-level mesh of trees is p = 2l(3 × 2l−2 − 1).
p. 253 [050523] Add the following explanation to part b of Problem 12.1: The restriction of interprocessor communication to a single dimension at a time for all processors is known as the uniaxis communication model.
p. 257 [001212r] Line 8: Change "q-D" to "qD".
p. 266 [020308b] In line 10 after Fig. 13.3, replace "a torus" with "a 2D torus".
p. 266 [020308c] In the last two lines before Fig. 13.4, remove the open parenthesis after "sizes" and the closed parenthesis at the very end.
p. 268 [170313] On line –4, change "congestion q" to "congestion 1" and delete "congestion and" at the end of line –4 and beginning of line –3.
p. 276 [020308] At the end of Problem 13.6, change "from 0 to 2q − 2" to "from 1 to 2q − 1". {The original statement is not incorrect, but the modified statement makes the solution somewhat cleaner.}
p. 277 [010521a] Part a of Problem 13.13: Change "back substitution" to "forward substitution".
p. 290 [001212s] Fig. 14.7 caption should read: Packing is a "good" problem for dimension-order routing on the hypercube.
p. 291 [001212t] Fig. 14.8 caption should read: Bit-reversal permutation is a "bad" problem for dimension-order routing on the hypercube.
p. 305 [001212u] Line 7: 0(2q) should be o(2q); i.e., change "0" to lower case roman "oh".
p. 314 [010521b] On the next to the last line (above Fig. 15.17), at the beginning of the line, "011011" should be replaced with "01011011". {The leftmost 0 should remain underlined.}
p. 318 [081107b] In Problem 15.9, line 3, change "cube-connected cycles networks" to "cube-connected cycles network".
p. 319 [030220b] In Problem 15.11, part d, italicize the last occurrence of x on the last line.
p. 328 [050523a] On line 6, the diameter of star graph should be given as ⌊3(q − 1)/2⌋, instead of 2q − 3.
p. 328 [050523b] On line 7, Change "optimal" to "suboptimal" and delete the sentence beginning with "Note, however".
p. 341 [050523c] On line 4 of Problem 16.4, change "the other 2q bits" to "the other 2q − 2 bits".
p. 341 [081107c] In part d of Problem 16.5, change 2q − 3 to ⌊3(q − 1)/2⌋.
p. 350 [010601] Line 2 from bottom of page: Change "five-node graph" to "four-node graph".
p. 361 [010601a] Line 16: Change "upper bound for" to "approximation to".
p. 361 [010521c] Line 17: In the formula for speed-up, change "≤ =" to "≈".
p. 366 [040105] In part a of Problem 17.12, change "scheduling theorem" to "scheduling algorithm".
p. 376 [020311] In Fig. 18.4, change the label of the topmost horizontal arrow, going from the "Exclusive" state to the "Shared" state, to: Read miss: Fetch data value, return data value, sharing set = sharing set + {c}
p. 405 [050523d] On line 31, change "P4 being the only healthy unit" to "P3 being the only healthy unit".
p. 435 [001213f] Part c of problem 20.9: Change "with" to "WITH".
Additions to the Text, and Internet Resources

This section includes extended and alternate explanations for some topics in the textbook. Also, updates to the material are presented in the form of new references (both print and electronic) and additional topics/problems. Like the list of errors in the previous section, the items that follow are organized by page numbers in the textbook and identified by date codes in square brackets. Four new chapters, planned for the next revision of the textbook, are described in a separate section below.
p. 55 [001212d] Evidence for the suspicion that NC ≠ P fall into three categories [Gree95, pp. 61-70]:
a. The best general simulations of sequential models yield modest speed-ups of log T or sqrt(T), where T is the sequential time. Furthermore, these simulations need 2^(T^W(1)), or exponentially many, processors. A fast general simulation would allow us to run sequential programs in parallel with good speed-up. Such a "super" parallelizing compiler is impractical.
b. All known fast simulations (parallelizations) have very limited domains of applicability. For example, we know that certain machines with limited resources (e.g., time and space) can recognize languages that are in NC but that the resources must increase exponentially to cover all languages in P. Hence, NC = P would mean that this exponential increase in resources does not add to the machine's computing power. This is quite unlikely.
c. Certain natural approaches to parallelization have been proven to be insufficient.
For a list of P-complete problems, see [Gree95, pp. 119-220]. Open problems, that are not known to be P-complete or in NC, are listed in [Gree95, pp. 221-243].
[Gree95] Greenlaw, R., H. J. Hoover, and W. L. Ruzzo, Limits to Parallel Computation: P-Completeness Theory, Oxford University Press, 1995.
p. 79 [020104] Before last paragraph add: Both LogP and BSP models take the network bandwidth limitation into account on a per-processor basis. It is also possible to impose a global bandwidth limit (of, say, p/g). This can be shown to lead to a fundamentally stronger model [Adle99] that should not be used if the hardware in fact imposes a per-processor limit.
[Adle99] Adler, M., P. B. Gibbons, Y. Matias, and V. Ramachandran, "Modeling Parallel Bandwidth: Local versus Global Restrictions," Algorithmica, Vol. 24, pp. 381-404, 1999.
p. 125 [001212g] At the end of Section 6.6, add: For a good discussion of hot-spot contention, see [Dand99].
[Dand99] Dandamudi, S. P., "Reducing Hot-Spot Contention in Shared-Memory Multiprocessor Systems," IEEE Concurrency, Vol. 7, No. 1, pp. 48-59, January-March 1999.
p. 141 [010919] Becker, Nassimi, and Perl [Beck98] provide a generalization of periodic sorting networks of Dowd et al. [Dowd89] that leads to a large class of similarly structured networks with identical latencies. The networks of Dowd et al. represent one extreme (the most complex) in this class. The networks at the other extreme (the simplest) have n/2 − 1 fewer comparators in each of their log2n stages.
[Beck98] Becker, R. I., D. Nassimi, and Y. Perl, "The New Class of g-Chain Periodic Sorters," J. Parallel and Distributed Computing, Vol. 54, pp. 206-222, 1998.
p. 209 [010105] Problem 10.14: A comprehensive survey of interval routing appears in [Gavo00].
[Gavo00] Gavoille, C., "A Survey of Interval Routing," Theoretical Computer Science, Vol. 245, pp. 217-253, 28 August 2000.
 p. 213 [001212h] The opposite diagram complements Fig. 11.1 (shows how Fig. 11.1 was derived).
p. 213 [001212h] The opposite diagram complements Fig. 11.1 (shows how Fig. 11.1 was derived).
p. 233 [001212q] Add [Math87] to the reference list for Chapter 11. {Contains a good exposition of matrix algorithms, including LU factorization and its comparison with Gaussian elimination.}
[Math87] Mathews, J. H., Numerical Methods for Computer Science, Engineering, and Mathematics, Prentice Hall, 1987.
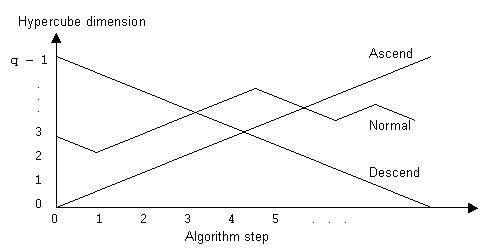 p. 312 [001212v] The opposite diagram is a graphical representation of the communication pattern in ascend, descend, and normal hypercube algorithms.
p. 312 [001212v] The opposite diagram is a graphical representation of the communication pattern in ascend, descend, and normal hypercube algorithms.
p. 330 [140419] At the end of the first full paragraph, replace "4 + 4 + 4 = 12." with "4*2 + 4*2 + 4 = 20."
p. 343 [001213] Add [Lisz97] to the reference list for Chapter 16. {Good overview paper, suggesting that fair comparison of networks is difficult. We don't know if analytically tractable models can predict real behavior. It is not clear how diverse networks used within distinct architectures can be compared with regard to cost-effectiveness.}
[Lisz97] Liszka, K. J., J. K. Antonio, and H. J. Siegel, "Problems with Comparing Interconnection Networks: Is an Alligator Better than an Armadillo?", IEEE Concurrency, Vol. 5, No. 4, pp. 18-28, October-December 1997.
p. 378 [001213a] Before the last paragraph of Section 18.3, add: Within certain limits, multithreading may have the same effect on performance as parallel processing. The results of [Sato99] show that for some numerical applications, performance depends on the product of the number of nodes and the number of threads. For example, in multiplying large matrices, the speed-ups achieved are almost identical with 2 nodes at 4 threads, 4 nodes at 2 threads, and 8 nodes at a single thread.
[Sato99] Sato, M., "COMPaS: A PC-Based SMP Cluster," IEEE Concurrency, Vol. 7, No. 1, pp. 82-86, January-March 1999.
p. 398 [001213b] At the end of the next to last paragraph, add: However, if we are allowed to change the external connections to the array, so that either the top or bottom row (leftmost or rightmost column) can be viewed as a spare row (column), then all triple defects and a larger fraction of other defect patterns become tolerable.
p. 404 [001213c] At the end of the first full paragraph, add: For a review of algorithm-based fault tolerance methods, see [Vija97].
[Vija97] Vijay, M. and R. Mittal, "Algorithm-Based Fault Tolerance: A Review," Microprocessors and Microsystems, Vol. 21, pp. 151-161, 1997.
p. 418 [001213d] After the description of Fig. 20.2 in Section 20.1, add: For a discussion of hot-spot contention in shared-memory systems, see the end of Section 6.6.
p. 427 [001213e] Section 20.3 — For updates on PVM see: www.netlib.org/pvm3/book/node1.html
p. 457 [001213g] Add [Dahl99] to the reference list for Chapter 21. {Reviews simple, hierarchical, and flat COMA architectures and qualitatively compares them to NUMA variants. Concludes that a combined architecture allowing NUMA/COMA handling of data on a per-page basis may be the best solution.}
[Dahl99] Dahlgren, F. and J. Torrellas, "Cache-Only Memory Architectures," IEEE Computer, Vol. 32, No. 6, pp. 72-79, June 1999.
p. 464 [001213h] An excellent introduction to Myricom's Myrinet switch can be found in [Bode95].
[Bode95] Boden, N. J., et al., "Myrinet: A Gigabit-per-Second Local Area Network," IEEE Micro, Vol. 15, No. 1, pp. 29-36, February 1995.
p. 508 [020104a] For an update on the course of the ASCI program, including data on the 3 TFLOPS Blue Pacific (IBM, at Lawrence Livermore Lab), the 3 TFLOPS Blue Mountain (SG/Cray, at Los Alamos), and the 12 TFLOPS ASCI White (IBM), see [Clar98]. ASCI White is also described and depicted in the November 2001 issue of IEEE Spectrum, pp. 29-31.
[Clar98] Clark, D., "ASCI Pathforward: To 30 Tflops and Beyond," IEEE Concurrency, Vol. 6, No. 2, pp. 13-15, April-June 1998.
p. 508 [001213i] An overview of the Intel Pentium Pro project can be found in [Papw96]. For information on a competing processor architecture, the MIPS R10000, see [Yeag96].
[Papw96] Papworth, D. B., "Tuning the Pentium Pro Microarchitecture," IEEE Micro, Vol. 16, No. 2, pp. 8-15, April 1996.
[Yeag96] Yeager, K. C., "The MIPS R10000 Superscalar Microprocessor," IEEE Micro, Vol. 16, No. 2, pp. 28-40, April 1996.
Four New Chapters for Part II (Now Parts II' and II")

Since the publication of Introduction to Parallel Processing: Algorithms and Architectures in 1999, the field it covers has undergone significant changes. One of the changes pertains to the shared-memory model assuming greater significance, both as an implementation alternative and as an abstraction that facilitates the construction of, and reasoning about, parallel programs. Another change is a rise in the importance of the circuit model of parallel computation that characterizes many application-specific designs and hardware accelerators, as well as allowing us to study the fundamental limits of speed and the corresponding speed/cost/energy tradeoffs.
Originally, descriptions of the shared-memory and circuit models were packed into Part II of the text, bearing the title "Extreme Models," because the two models could be viewed as representing the most abstract and most concrete extremes. Now, it seems appropriate for shared-memory and circuit models to be described in greater detail and with more examples. Thus, it was decided to split Part II of the book into two new Parts, II' and II", each with four chapters. New material associated with this revision and expansion will be posted here as they become available. To maintain the numbering of parts and chapters for the rest of the book, the new Part II' consists of the original Chapter 5 and the three Chapters 6A, 6B, and 6C replacing the original Chapter 6. Similarly, Part II" incorporates the original Chapter 7 and includes Chapters 8A, 8B, and 8C as replacements for the original Chapter 8.
The following Part, Chapter, and Section titles should be viewed as tentative; they may change as the material is prepared and finalized.
Part II': Shared-Memory Parallelism
5 PRAM and Basic Algorithms ~
5.1 PRAM Submodels and Assumptions ~
5.2 Data Broadcasting ~
5.3 Semigroup or Fan-in Computation ~
5.4 Parallel Prefix Computation ~
5.5 Ranking the Elements of a Linked List ~
5.6 Matrix Multiplication
6A More Shared-Memory Algorithms ~
6A.1 Parallel Searching Algorithms ~
6A.2 Sequential Ranked-Based Selection ~
6A.3 A Parallel Selection Algorithm ~
6A.4 A Selection-Based Sorting Algorithm ~
6A.5 Alternative Sorting Algorithms ~
6A.6 Convex Hull of a 2D Point Set
6B Implementation of Shared Memory ~
6B.1 Processor-Memory Interconnection ~
6B.2 Multistage Interconnection Networks ~
6B.3 Cache Coherence Protocols ~
6B.4 Data Allocation for Conflict-Free Access ~
6B.5 Distributed Shared Memory ~
6B.6 Methods for Memory Latency Hiding
6C Shared-Memory Abstractions ~
6C.1 Atomicity in Memory Access ~
6C.2 Strict and Sequential Consistency ~
6C.3 Processor Consistency ~
6C.4 Weak or Synchronization Consistency ~
6C.5 Other Memory Consistency Models ~
6C.6 Transactional Memory
Part II": Circuit-Level Parallelism
7 Sorting and Selection Networks ~
7.1 What is a Sorting Network? ~
7.2 Figures of Merit for Sorting Networks ~
7.3 Design of Sorting Networks ~
7.4 Batcher Sorting Networks ~
7.5 Other Classes of Sorting Networks ~
7.6 Selection Networks
8A Search Acceleration Circuits ~
8A.1 Systolic Priority Queues ~
8A.2 Searching and Dictionary Operations [Current Section 8.1] ~
8A.3 Tree-Structured Dictionay Machines [Current Section 8.2] ~
8A.4 Associative Memories ~
8A.5 Associative Processors ~
8A.6 VLSI Trade-offs in Search Processors
8B Arithmetic and Counting Circuits ~
8B.1 Basic Addition and Counting ~
8B.2 Circuits for Parallel Counting ~
8B.3 Addition as a Prefix Computation [Current Section 8.3] ~
8B.4 Parallel Prefix Networks [Current Section 8.4] ~
8B.5 Multiplication and Squaring Circuits ~
8B.6 Division and Square-Rooting Circuits
8C Fourier Transform Circuits ~
8C.1 The Discrete Fourier Transform [Part of the current Section 8.5, plus some applications] ~
8C.2 Fast Fourier Transform (FFT) [Part of the current Section 8.5] ~
8C.3 The Butterfly FFT Network [Part of the current Section 8.6] ~
8C.4 Mapping of Flow Graphs to Hardware ~
8C.5 The Shuffle-Exchange Network [Part of the current Section 8.6] ~
8C.6 Other Mappings of the FFT Flow Graph [Part of the current Section 8.6]