|
Asking for Help with the Right Question by Predicting Human Visual Performance (RSS16) |
|
This is a project summary page for the following paper:
H. Cai and Y. Mostofi, "Asking for Help with the Right Question by Predicting Human Visual Performance," Robotics: Science and Systems (RSS), June 2016.
Faculty: Yasamin Mostofi
PhD Student: Hong (Herbert) Cai
Robots are becoming more capable of accomplishing complicated tasks these days. There, however, still exist many tasks that robots cannot autonomously perform to a satisfactory level. As such, robots can benefit tremendously from asking humans for help. However, human performance may also be far from perfect depending on the given task.
In this paper, we consider visual tasks (object detection, object classification, visual search, etc.) and equip the robot with the ability to predict human visual performance. More specifically, a robot is given a perception task and has a limited access to a remote human operator to ask for help. However, human visual performance may also be far from perfect depending on the sensory input. Our contribution is then two-fold: 1) Proposing a way of probabilistically predicting human visual performance for any visual input, and 2) Co-optimizing field sensing, navigation, and human collaboration based on this probabilistic metric. This will allow the robot to ask for help when humans can indeed be of help.
|
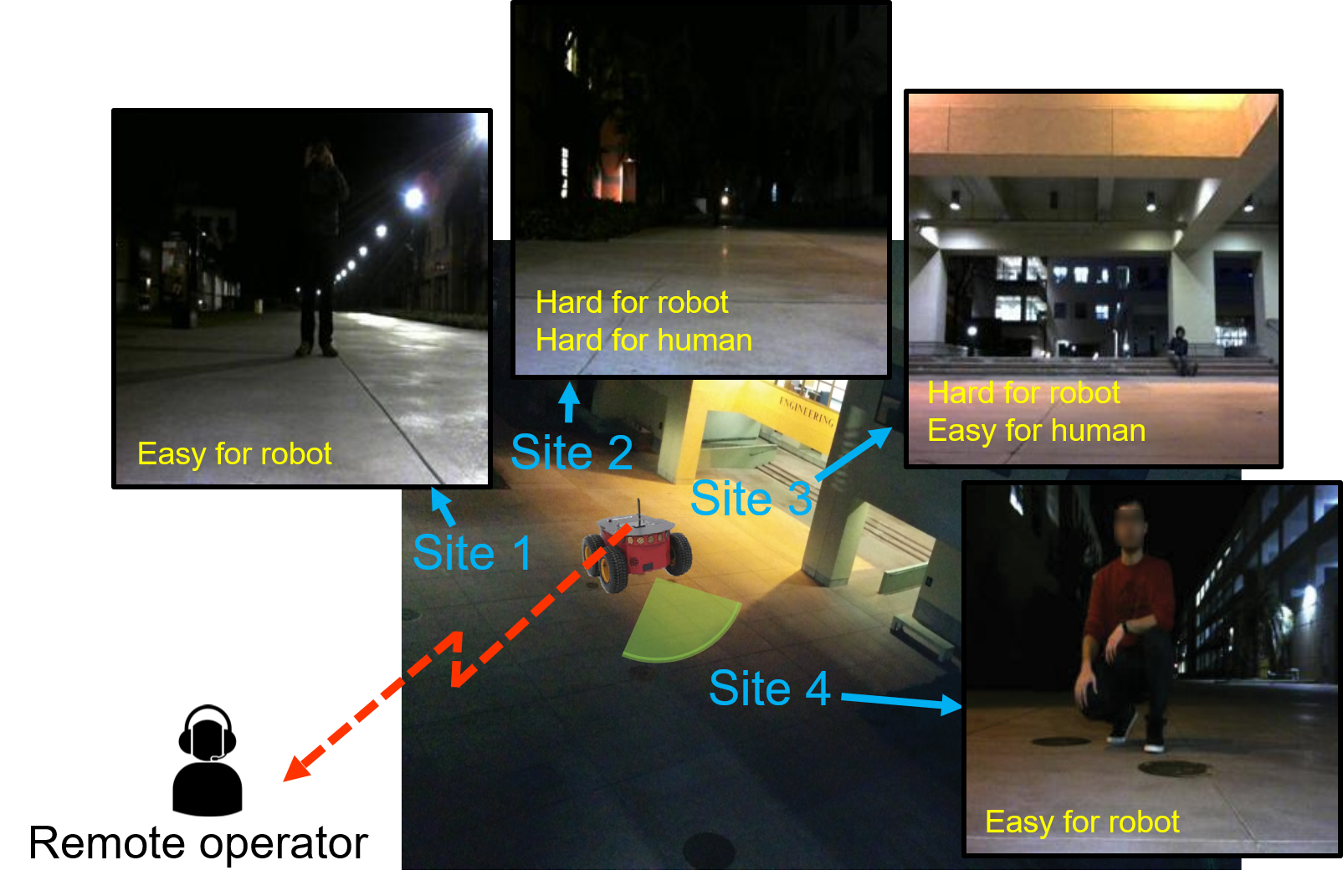
Fig. 1 above demonstrates a real example of this for a robotic surveillance task on our campus. An unmanned ground vehicle is given a visual perception task that involves finding the human at each of the 4 shown sites, based on onboard camera inputs. The robot has a limited access to a remote human operator to ask for help with this task. The figure shows the images taken by the robot after its initial sensing of each site. Equipped with a state-of-the-art vision algorithm, the robot can easily recognize the human at Sites 1 and 4. However, the robot's vision fails for Sites 2 and 3. On the other hand, the person at Site 3 can be easily detected by a human, while it is also hard for humans to spot the person at Site 2. Thus, the optimum decision would involve for the robot go go to Site 2 for further sensing and to seek assistance for Site 3. In this paper, we enable the robot with the needed tools to make this correct decision.
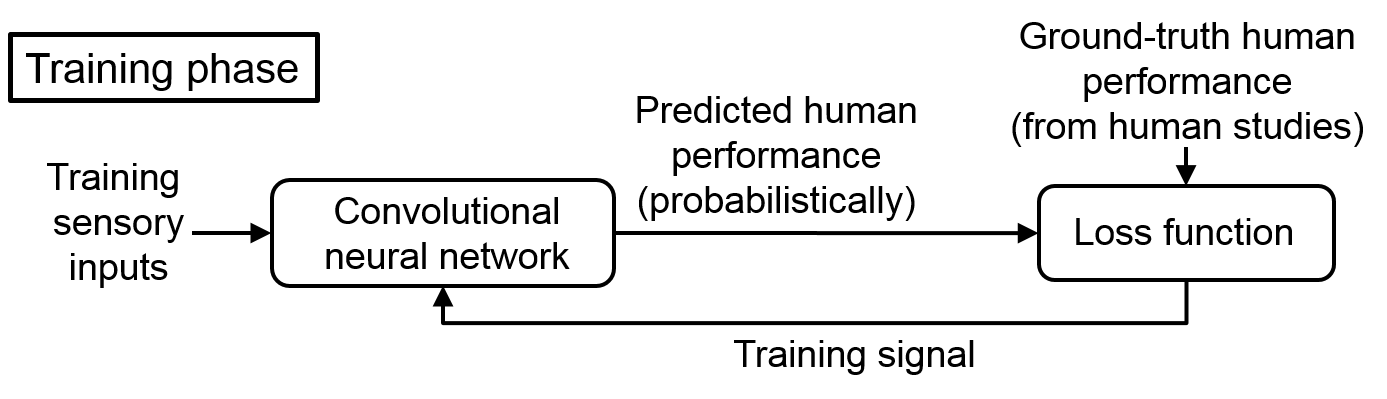
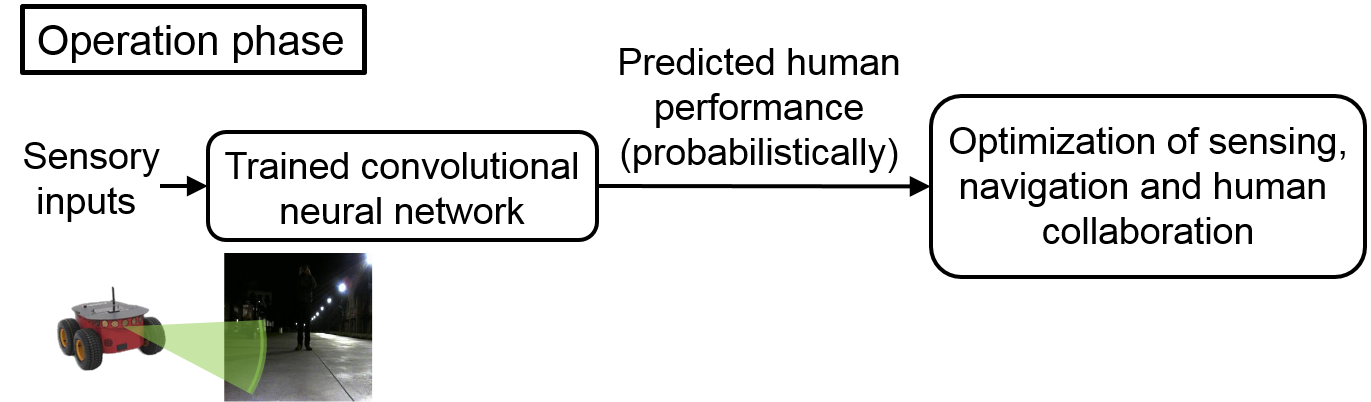
Our methodology consists of two main parts. First, at the core of our approach is a proposed probabilistic predictor for human visual performance, which allows the robot to probabilistically assess human performance for any given sensory input. This enables the robot to ask the right questions, only querying the operator with the sensory inputs for which humans have a high chance of success. Then, the robot uses the feedback from our predictor to co-optimize its human collaboration and field sensing/navigation. The two block diagrams below summarize the proposed methodology.
We utilize a Convolutional Neural Network (CNN) to predict human performance. We train our CNN by gathering several human data using Amazon Mechanical Turk (MTurk). See the paper for more details.
 |
Based on the output of the human predictor, the robot then optimizes its field decision making in terms of relying on itself, asking for help, and further sensing/navigation, under a limited energy budget. See the paper for more details.
 |
Below are four sample images. The task is to find the person in each image, given there is a person in each image. Each image shows the true probability that humans can accomplish this task (based on several MTurk surveys) as well as our prediction based on our trained CNN. Click on the images to see them shown in the original size (256×256) and as viewed by human operators.

|
The table below shows the performance (Normalized Mean Squared Error) of our trained human predictor over the validation set and its different subsets.
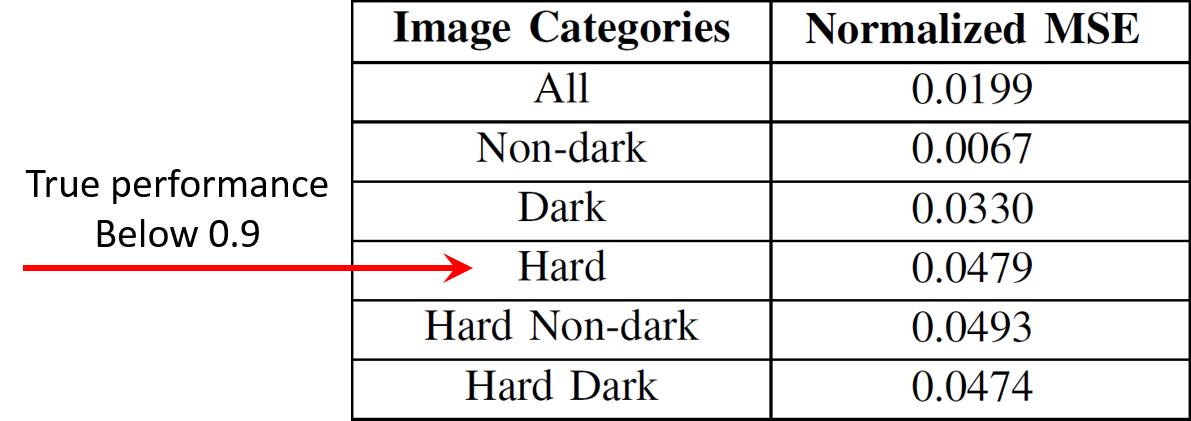 |
For more extensive details of the performance of the predictor, see the paper.
We have extensively tested the proposed approach with several real experiments on our campus as well as in simulation environments. Here we present three sample experimental results on our campus. See the paper for more results. To see these experimental images in the original 256×256 size and as viewed by human operators, see the supplementary material.
In each experiment, the robot starts at the center of a crossroad. Each crossroad direction is a site of interest, and there is a person at each site. The robot is tasked with finding the person in each site based on camera inputs, and is given a maximum of 1 question to ask the remote operator for help with finding the person in that experiment. The robot can also choose to move to a site for further sensing. The goal of the robot is to find the person in each direction with a very high probability, while minimizing its total energy usage. It has three possible decisions for each site: 1) rely on itself (i.e., its initial sensing), 2) ask humans for help, or 3) move to the site for better sensing.
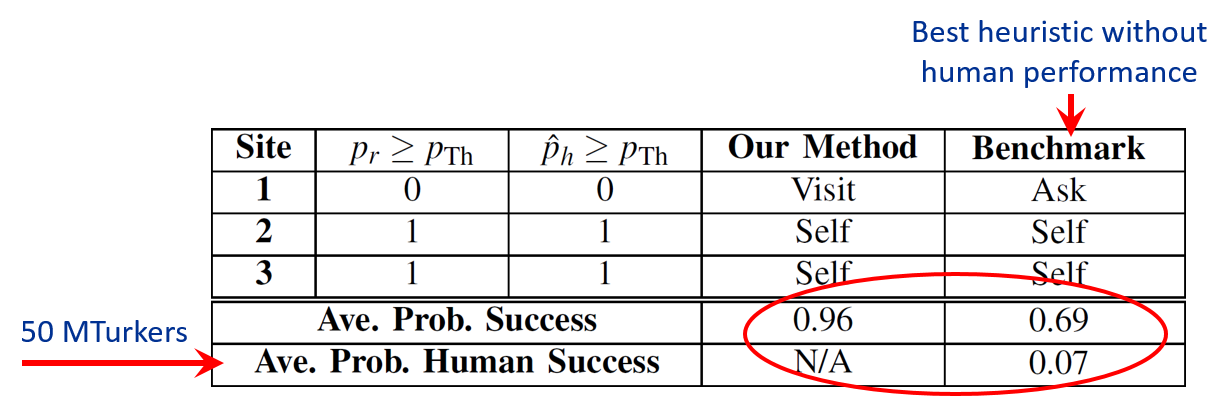
The following figures show the initial sensing images of 3 sites at crossroad 1, followed by the image taken after moving to Site 1 for further sensing based on our approach. It can be seen that the benchmark sends Site 1 to humans for help, which has a near-zero chance of humans being able to find the person in the image. Our approach, on the other hand, predicts this low probability and decides to instead visit this site for further sensing. The table also shows the overall average probability of task accomplishment, which is 0.69 for the benchmark and 0.96 for our approach (39% higher than benchmark).
 |
 |
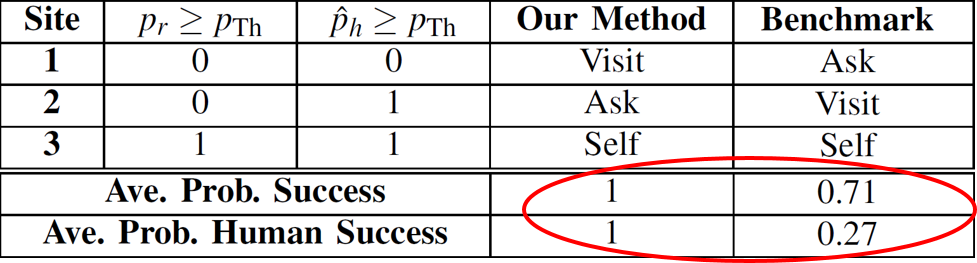
The following figures show the initial sensing images of 3 sites at crossroad 2, followed by the image taken after moving to Site 1 for further sensing based on our approach. Sites 1 and 2 are hard for the robot based on its initial sensing. Our approach then optimally decides that Site 2 is easy for humans while Site 1 is difficult, deciding to visit Site 1 and ask for help with Site 2. The table also shows the overall average probability of task accomplishment, which is 0.71 for the benchmark and 1 for our approach (41% higher than benchmark), with the human success rate of 1 for our approach vs. 0.27 for the benchmark.
 |
 |
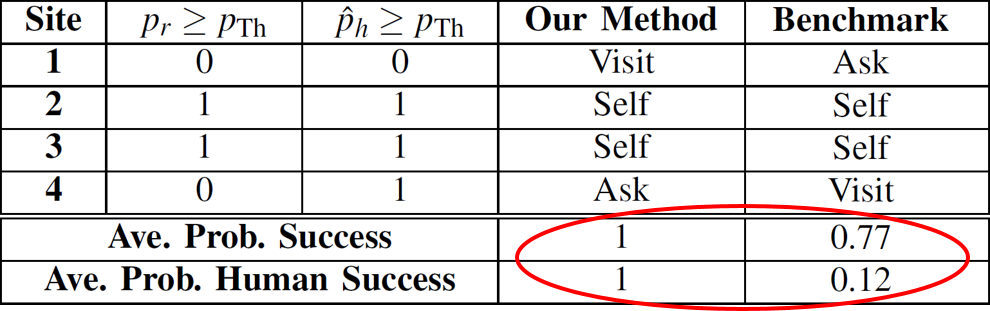
The following figures show the initial sensing images of 4 sites at crossroad 3, followed by the image taken after moving to Site 1 for further sensing based on our approach. Sites 1 and 4 are hard for the robot based on its initial sensing. Our approach then optimally decides that Site 4 is easy for humans while Site 1 is difficult, deciding to visit Site 1 and ask for help with Site 4. The table also shows the overall average probability of task accomplishment, which is 0.77 for the benchmark and 1 for our approach (30% higher than benchmark), with the human success rate of 1 for our approach vs. 0.12 for the benchmark.
 |
 |
We have released our human performance data and prediction code. See the data and code site for the data/code and a detailed documentation. Alternatively, the zipped folder can be directly downloaded from here. For more details on how we collected our data and the training procedures, please refer to the paper.
If you have any questions or comments regarding the data and/or the code, please contact Herbert Cai.
The code/data are owned by UCSB and can be used for academic purposes only.
If you have used this data and/or code for your work, please refer the readers to the data and code site at its DOI address: https://doi.org/10.21229/M9V66F, and also cite the following paper:
H. Cai and Y. Mostofi, "Asking for Help with the Right Question by Predicting Human Visual Performance," Robotics: Science and Systems (RSS), June 2016.
@inproceedings{CaiMostofi_RSS16_Ask,
title={Asking for Help with the Right Question by Predicting Human Visual Performance},
author={H. Cai and Y. Mostofi},
booketitle={Proceedings of Robotics: Science and Systems},
year={2016}}
In other papers, we have also extensively considered the path planning aspects of human-robot collaboration. More specifically, given a probabilistic human performance predictor, we have extensively studied the mathematical properties of the optimum decisions in terms of sensing, path planning, and communication with the human operator, in the following papers.